

Estamos frente a una máquina, queremos extraer de ella un tipo determinado de archivos pero tenemos muy poco tiempo. Podríamos buscar en los directorios, copiar los archivos que nos interesan, comprimirlos y guardarlos en una memoria USB pero ya lo dije: tenemos muy poco tiempo. Por eso creé en Python unos scripts para extraer documentos que me permiten hacer esta tarea en segundos.
Hackear es resolver problemas técnicos de forma sencilla. Las tonterías de sótanos oscuros con diez terminales de letras verdes sobre fondos negros y un fumador sin rostro irrumpiendo en agencias secretas del gobierno dejémoslas para Hollywood. El 95% del hacking es hacer estas pendejadas, pendejadas que nos pueden arrojar resultados muy valiosos.
El primer script lo hice pensando en extraer archivos PDF de las carpetas Documentos y Descargas, donde normalmente se guardan. Este superprograma de 33 líneas pesó 1,1 kB.
En la siguiente imagen veremos que el script funcionó de maravilla y extrajo todos los archivos con extensión .pdf de las carpetas indicadas.
Después pensé que no tenía sentido limitar la extracción a unas cuantas carpetas si podía hacerlo al nivel de todo el directorio principal. El nuevo código quedó más pequeño: 28 líneas y menos de 1 kB (906 bytes).
Como veremos en la siguiente imagen, ahora pude extraer más archivos que con el primer código (obvio).
Pero después pensé que siendo una operación tan rápida podía extenderla a varios tipos de archivos. Para ello agregué la siguiente línea de código: extensiones = [".pdf", ".docx", ".xlsx", ".xls", ".doc", ".jpg", ".jpeg", ".png"] y el nuevo script con 32 miserables líneas de código quedó así:
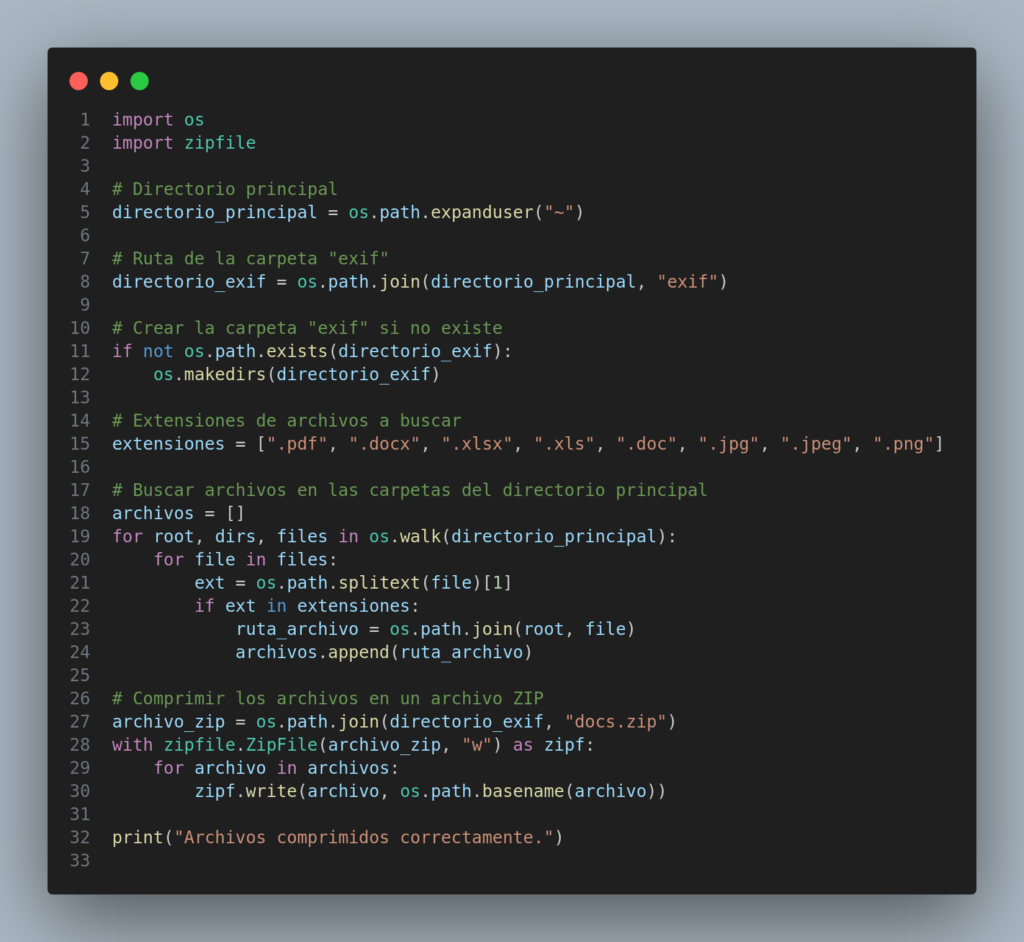
Ahora la recuperación de archivos fue una locura. Centenares de archivos comprimidos y listos para descargar. Ya valía la pena la exfiltración. En la carpeta había hojas de cálculo, correspondencia con entidades, cotizaciones, contratos, fotos, capturas de pantalla etc.
Con un script tan sencillo como este podemos hacer muchas cosas. Ahora tenía que probarlo en Mocosoft Windows que es el sistema operativo instalado en la mayoría de ordenadores personales del mundo. El resultado fue estupendo:
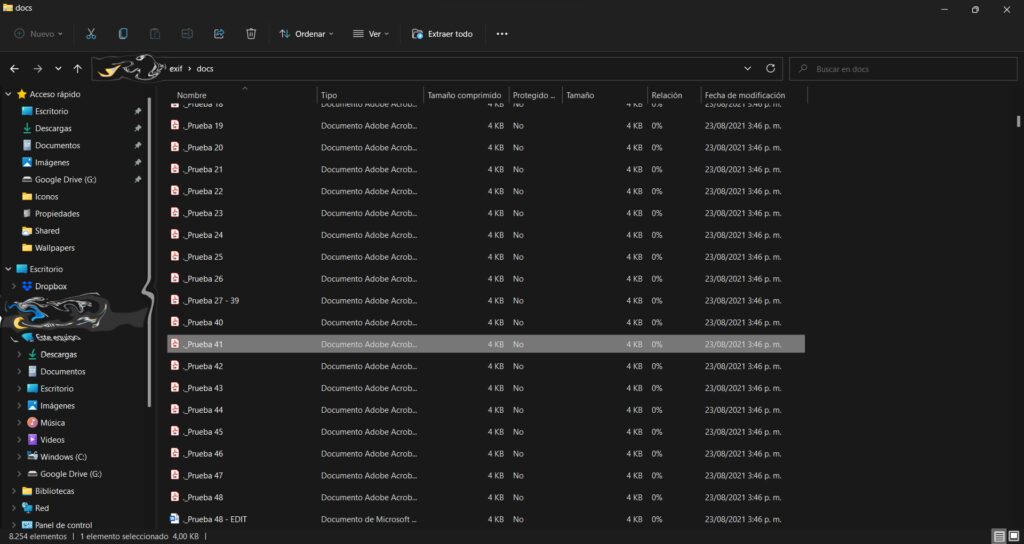
8.254 archivos extraídos en 12 segundos con un script de 32 líneas y que pesa 1 kB. Esa es la definición misma de Eficiencia.
| Por cierto no escribí este script para robar archivos. Confesarlo en línea sería algo muy estúpido. El propósito de este código es, en primer lugar, compartir ejercicios simples pero muy prácticos de Python y, en segundo, acceder rápidamente a un tipo específico de archivos en mis propias máquinas. Aunque, pensándolo bien, también podría usarse para otros fines… Hasta la próxima. |










