

En posts anteriores hablé de cómo tener modelos de IA en nuestra máquina local sin pagar suscripciones. La opción que enseñé antes se basa en una aplicación GUI (interfaz gráfica). Ahora les voy a enseñar a tener la IA en la terminal (CLI). Esto supone un ahorro considerable de recursos y una mejora en los tiempos de respuesta. Veamos cómo hacerlo.
Ollama.
 La aplicación que vamos a usar para tener IA en la terminal se llama Ollama (Open source Library for AI Models and Applications). Como su nombre lo indica, es una aplicación de código abierto. No nos pide registro y, al parecer, respeta la privacidad de sus usuarios.
La aplicación que vamos a usar para tener IA en la terminal se llama Ollama (Open source Library for AI Models and Applications). Como su nombre lo indica, es una aplicación de código abierto. No nos pide registro y, al parecer, respeta la privacidad de sus usuarios.
Con Ollama podemos cargar en nuestra máquina los modelos de lenguaje de gran tamaño (LLM) y correrlos offline.
Ollama tiene versiones para GNU/Linux y también para los sistemas operativos de baja estofa como Windows y Mac 😳 … Para obtener Ollama y empezar a usar la IA en la terminal debemos ir a su sitio y descargar una copia. Yo lo haré para un sistema Debian 12 por lo cual usaré el siguiente comando:
curl -fsSL https://ollama.com/install.sh | sh
Y eso es todo. Al cabo de unos segundos ya tengo Ollama en mi equipo y puedo correr la IA en la terminal de comandos. Para comprobar la descarga enviaremos el comando ollama --version. Si ya la tenemos instalada veremos la versión de la herramienta, en este caso la 0.5.4. Ahora, podemos llamar a la ayuda de la herramienta con el comando ollama --help y ver todas sus opciones. Veamos algunas cositas básicas de la herramienta.
Cargar modelos.
En el sitio de Ollama vamos al apartado de modelos y elegimos el o los modelos que necesitemos. Debemos tener en cuenta las particularidades de nuestra máquina. Si tenemos un equipo con pocos recursos no vamos a descargar un modelo de 70B (70 billones de parámetros) como llama3.3 salvo que queramos que nuestra máquina explote.
Para este ejercicio voy a descargar dos modelos: llama3.2-vision en su versión de 11 billones de parámetros y zephyr de 7 billones. Los modelos podemos instalarlos con los comandos pull y run. La diferencia estará en que con run comenzará a usarlo tan pronto lo descargue. Los comandos serían entonces: ollama run llama3.2-vision o también ollama pull llama3.2-vision. En la terminal veremos lo siguiente:
$ ollama run llama3.2-vision pulling manifest pulling 11f274007f09... 100% ▕████████████████████████████████████▏6.0 GB pulling ece5e659647a... 100% ▕████████████████████████████████████▏1.9 GB pulling 715415638c9c... 100% ▕████████████████████████████████████▏269 B pulling 0b4284c1f870... 100% ████████████████████████████████████▏7.7KB pulling fefc914e46e6... 100% ▕████████████████████████████████████▏32B pulling fbd313562bb7... 100% ▕████████████████████████████████████▏572B verifying sha256 digest writing manifest success
Podemos comprobar que hayamos instalado los modelos con el comando ollama list. Para el caso de este ejercicio la salida fue:
NAME ID SIZE MODIFIED zephyr:latest bbe38b81adec 4.1 GB 2 minutes ago llama3.2-vision:latest 085a1fdae525 7.9 GB 15 minutes ago
Eso quiere decir que los LLM están en nuestro y equipo y ya podemos usarlos.
Usando IA en la terminal.
El uso de la IA en la terminal es muy pero muy sencillo. Con un comando le pedimos a la herramienta que lance un modelo. Por ejemplo: ollama run llama3.2-vision. En pantalla veremos el mensaje: >>> Send a message (/? for help). Lanzo la ayuda con /? y obtengo:
>>> /? Available Commands: /set Set session variables /show Show model information /load <model> Load a session or model /save <model> Save your current session /clear Clear session context /bye Exit /?, /help Help for a command /? shortcuts Help for keyboard shortcuts Use """ to begin a multi-line message. Use /path/to/file to include .jpg or .png images.
Tiene opciones muy interesantes. Me gusta que podamos guardar las sesiones para seguirlas usando en otro momento sin tener que comenzar de cero. También podemos incluir imágenes en nuestras sesiones dándole la ruta al modelo. Por ahora le haré unas preguntas simples a los dos modelos para compararlos.
Le pregunto a llama3.2-vision: ¿En qué consiste la vulnerabilidad XSS y cuántos tipos de ellas hay? La respuesta no está nada mal.
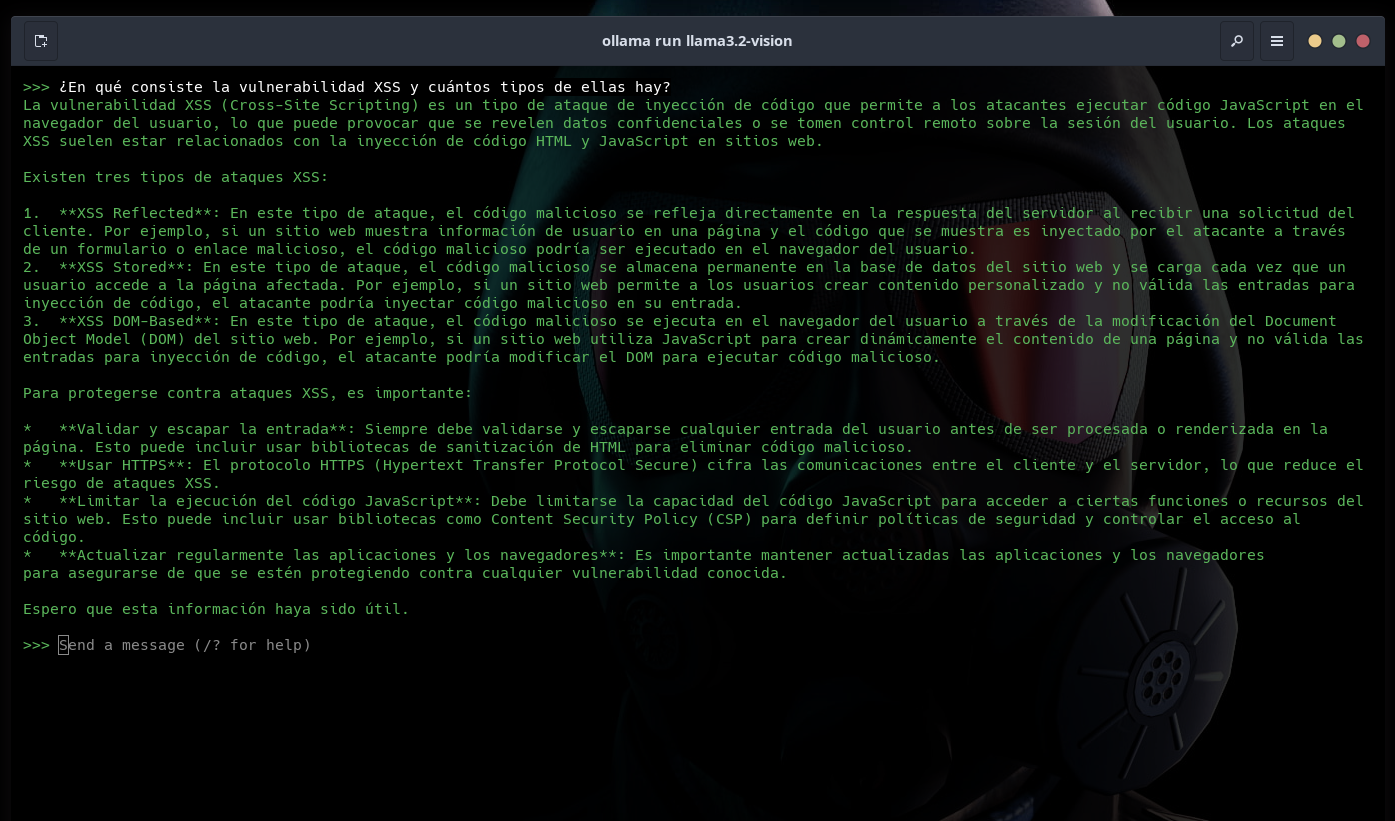
Salgo de este modelo con el comando /bye, cargo el otro modelo (zephyr) y le pregunto lo mismo. Su respuesta fue muy similar a la anterior:
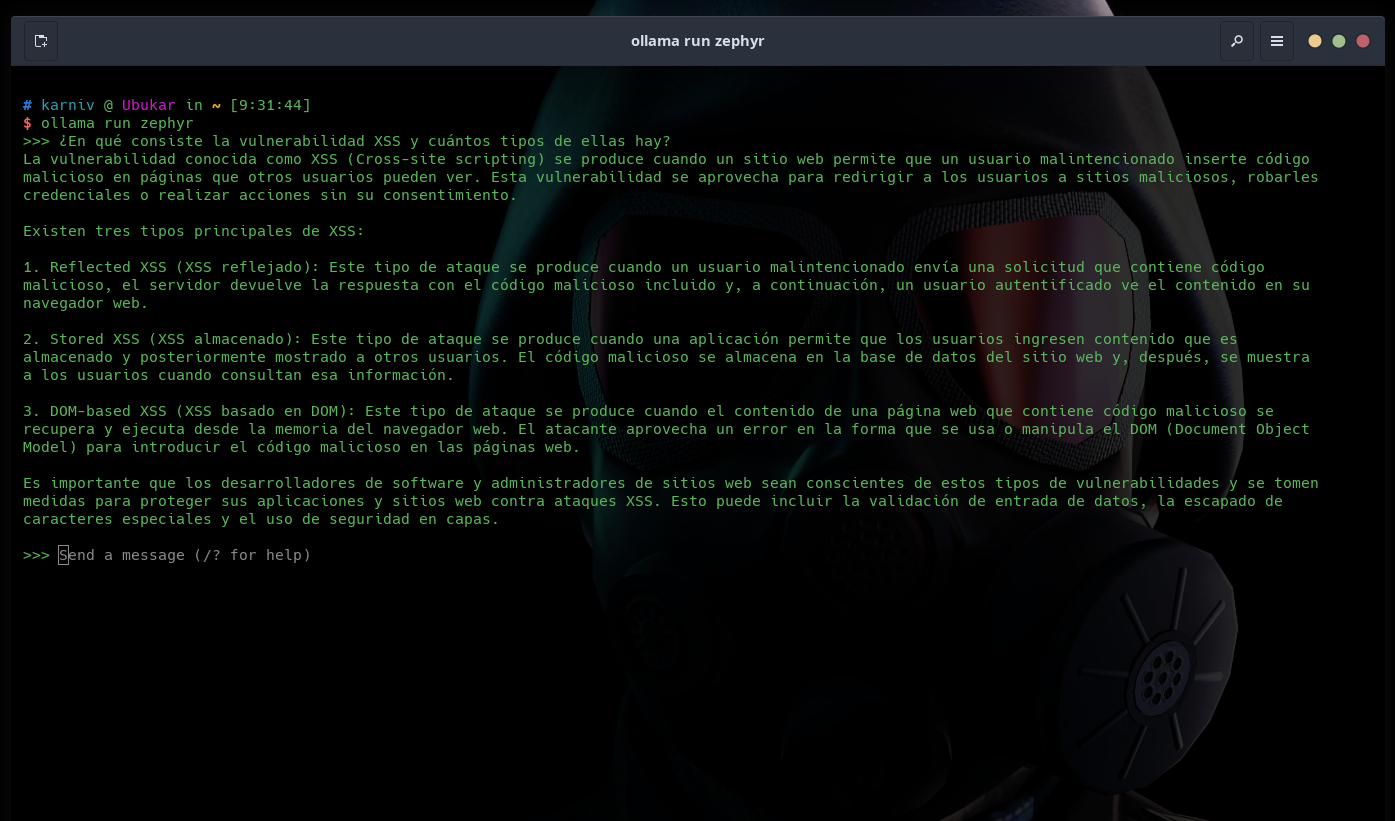
Los dos modelos fueron muy similares pero llama3.2-vision dio una respuesta un poco más completa. Era de esperarse ya que es un modelo más grande (11B Vs. 7B). Borro zephyr con el comando ollama rm zephyr y me quedo con el modelo que dio la mejor respuesta. Así hago espacio para probar otros LLM. Espero les sirva, hasta la próxima.










