

En una investigación OSINT necesitamos extraer información pública de un sitio web. Esto puede ser una tarea sencilla cuando se trata de sitios pequeños. Sin embargo, cuando se trata de sitios grandes, institucionales o corporativos, la labor puede ser tediosa, frustrante y desgastante. Un ejemplo de ello sería extraer correos electrónicos de un sitio web del gobierno o de una universidad.
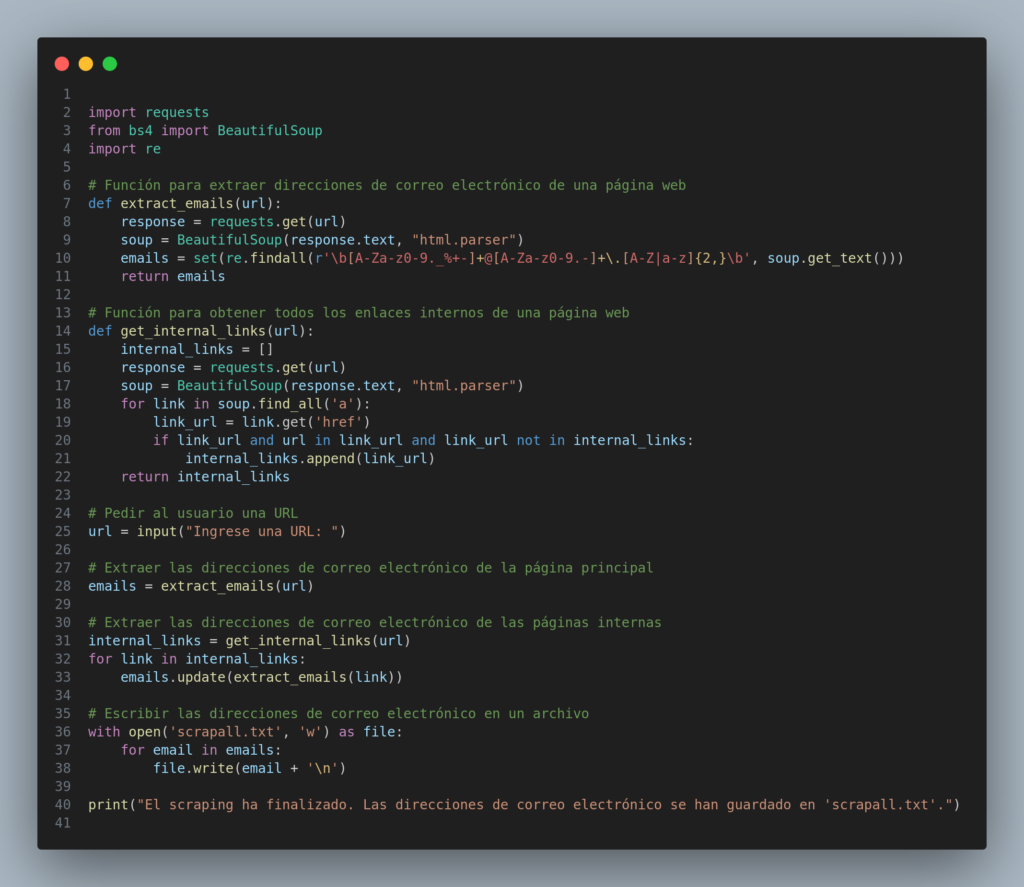
Por fortuna, podemos automatizar esta tarea con unas pocas líneas de código. Y eso fue lo que hice en Python. Creé un script de tan solo 40 líneas que se dirige a un sitio web, navega por sus enlaces internos, extrae la información que tenga formato de correo electrónico y la exporta a un archivo .txt.
De esto ya hay scripts en GitHub y en otros sitios pero yo quise hacerlo lo más sencillo posible y me funcionó. Mi archivo pesa 1,4 kB, no requiere instalar dependencias en el host y se corre directamente desde la terminal o desde VSC. Más fácil imposible.
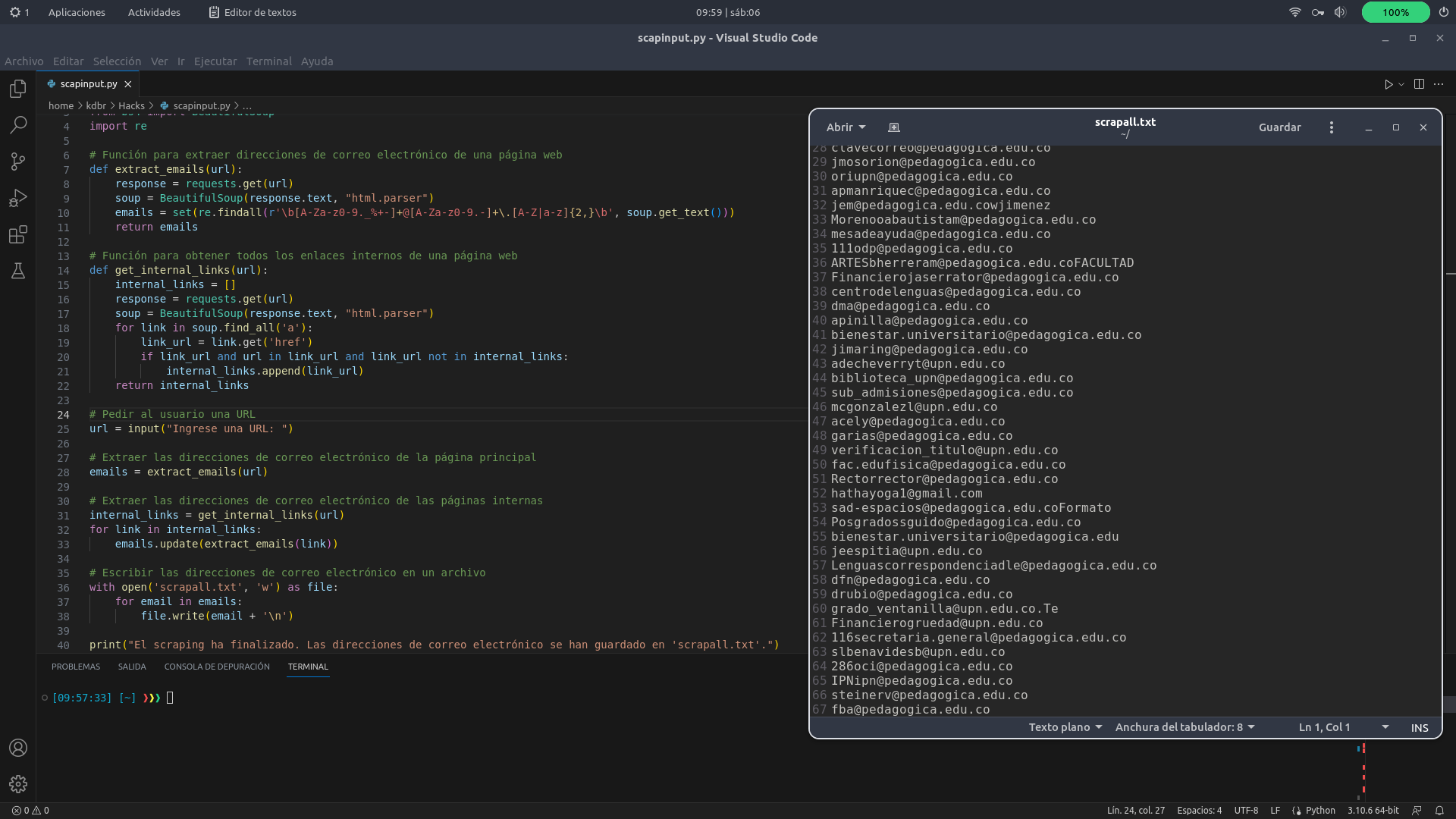
El script lo probé extrayendo los correos publicados en la web de una universidad colombiana. Lo único que hice fue crear un archivo con la extensión adecuada (nombre.py) y lo corrí desde VSC. Cuando el input me preguntó la web a la cual debía dirigirse, le di la dirección completa con https:// (en este caso https://www.upn.edu.co/) y listo. En menos de 1 minuto había extraído 67 direcciones de correo publicadas en la página.
Después, hice lo mismo desde la terminal de Ubuntu Linux dándole la instrucción de visitar una web del gobierno y obtuve 41 direcciones más. Esto puede ser muy útil cuando se trata de crear bases de datos, investigar una empresa o a sus funcionarios y encontrar alguna dependencia oculta o a alguien específico, entre muchos otros usos.
import requestsfrom bs4 import BeautifulSoupimport re# Función para extraer direcciones de correo electrónico de una página webdef extract_emails(url):response=requests.get(url)soup=BeautifulSoup(response.text, "html.parser")emails=set(re.findall(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', soup.get_text()))returnemails# Función para obtener todos los enlaces internos de una página webdef get_internal_links(url):internal_links= []response=requests.get(url)soup=BeautifulSoup(response.text, "html.parser")forlinkinsoup.find_all('a'):link_url=link.get('href')iflink_urlandurlinlink_urlandlink_urlnotininternal_links:internal_links.append(link_url)returninternal_links# Pedir al usuario una URLurl = input("Ingrese una URL: ")# Extraer las direcciones de correo electrónico de la página principalemails = extract_emails(url)# Extraer las direcciones de correo electrónico de las páginas internasinternal_links = get_internal_links(url)for link in internal_links:emails.update(extract_emails(link))# Escribir las direcciones de correo electrónico en un archivowith open('scrapall.txt', 'w') as file:foremailinemails:file.write(email+'\n')print("El scraping ha finalizado. Las direcciones de correo electrónico se han guardado en 'scrapall.txt'.")
El anterior es el código que utilicé para automatizar esta tarea. Como ven, es un código muy sencillo pero funciona, cumple su cometido. Es posible que algunos datos del output salgan sucios pero se pueden depurar fácilmente. Si creen que les puede servir, ahí lo tienen. Hasta la próxima.















